哈喽,大家好,我是指北君。
在我们做电商网站的时候,如果直接用传统的通过数据库去搜索数据,数据库内容比较少的情况下还能勉强做好及时搜索,但是如果成百上千的数据在数据库里面,你还是用传统的搜索数据库的方法,那就要等很长一段时间,影响用户体验,所以一般数据搜索引擎采用的是Elasticsearch来进行搜索。
1、Elasticsearch简介
全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elasticsearch是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎。Lucene只是一个框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene,学习成本高,且Lucene确实非常复杂。
文档:
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
官方中文(版本很旧,2.x):https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html
2、基本概念
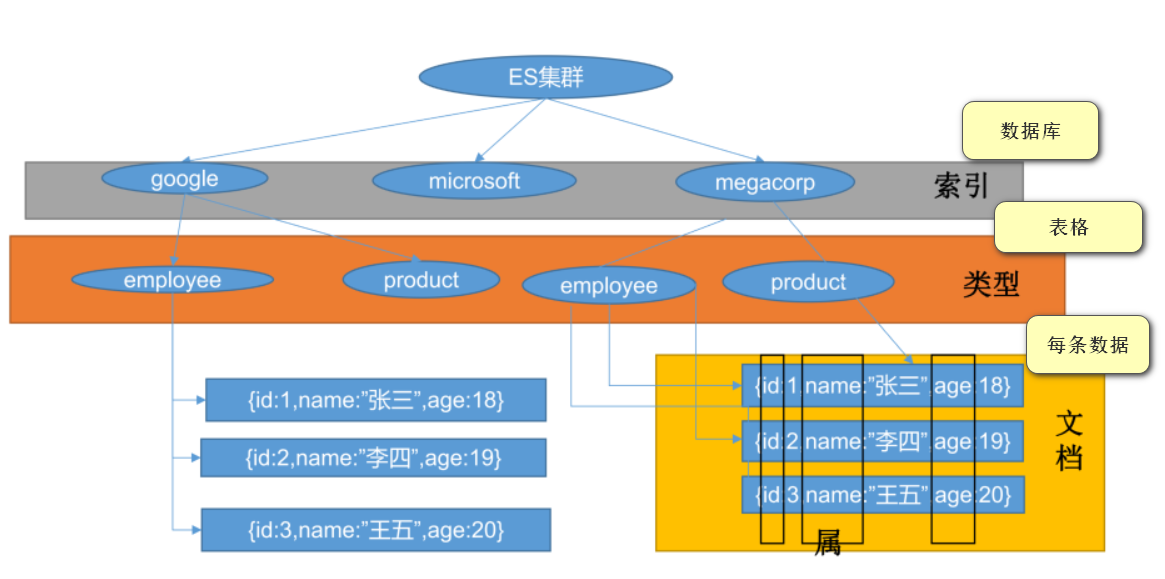
2.1 index(索引)
ES将数据存储于一个或多个索引中。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库database,或者一个数据存储方案(schema)。索引由其名称(必须为全小写字符)进行标识。一个ES集群中可以按需创建任意数目的索引。
2.2 Type(类型)
类型是索引内部的逻辑分区(category/partition),一个索引内部可定义一个或多个类型(type)。类比传统的关系型数据库领域来说,类型相当于“表”。
ElasticSearch7—去掉 type 概念:
- 关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch 是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed 最终在Lucene,中的处理方式是一样的。
- 两个不同 type下的两个user_ name, 在ES同-个索引下其实被认为是同一一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同typpe中的相同字段称就会在处理中出现神突的情况,导致Lucene处理效率下降。
- 去掉type就是为了提高ES处理数据的效率。
ES 7.x
URL 中的 type 参数 可选,比如索引一个文档不再要求提供文档类型
ES 8.X
不在支持 URL 中的 type 参数
解决:
1、将索引从多类型迁移到单类型,每种类型文档一个独立的索引
2、将已存在的索引下的类型数据,全部迁移到指定位置即可,详见数据迁移
2.3 Document(文档)
文档是索引和搜索的原子单位,它是包含了一个或多个域(Field)的容器,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”,文档基于JSON格式进行表示。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
简单来说:保存在某个索引(index)下,某种类型(Type)的一个数据(Document),文档是 JSON 格式的,Document 就像是 MySQL 中某个 Table 里面的内容。
2.4 Cluster(集群)
一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力。
2.5 节点(Node)
一个运行中的 Elasticsearch 实例称为一个节点。
ES集群中的节点有三种不同的类型:
主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
3、倒排索引
倒排索引: 倒排索引也叫反向索引,通俗来讲正向索引是通过key找value,反向索引则是通过value找key。
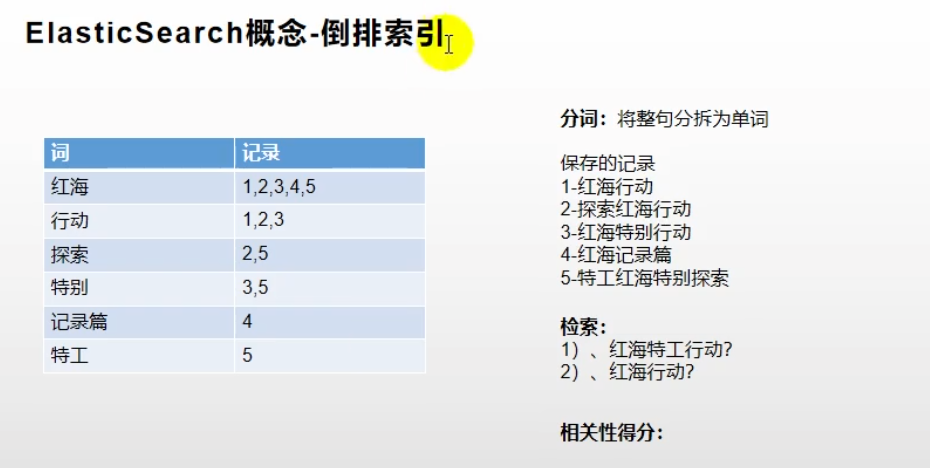
对每条要存储的文档进行分词,然后对每个词和所在的记录进行存储。在搜索时,先搜索含有其关键字的记录,然后对所记录计算相关性得分,得出最终的搜索结果。
4、Docker安装Elasticsearch
4.1 下载镜像文件
1 | |
4.2 创建实例
①、Elasticsearch
配置:
1 | |
启动:
1 | |
设置开启自启:
1 | |
特别注意:
-e ES_JAVA_OPTS=”-Xms64m -Xmx128m” \ 测试环境下,设置 ES 的初始内存和最大内存,否则导致过大启动不了ES
测试:
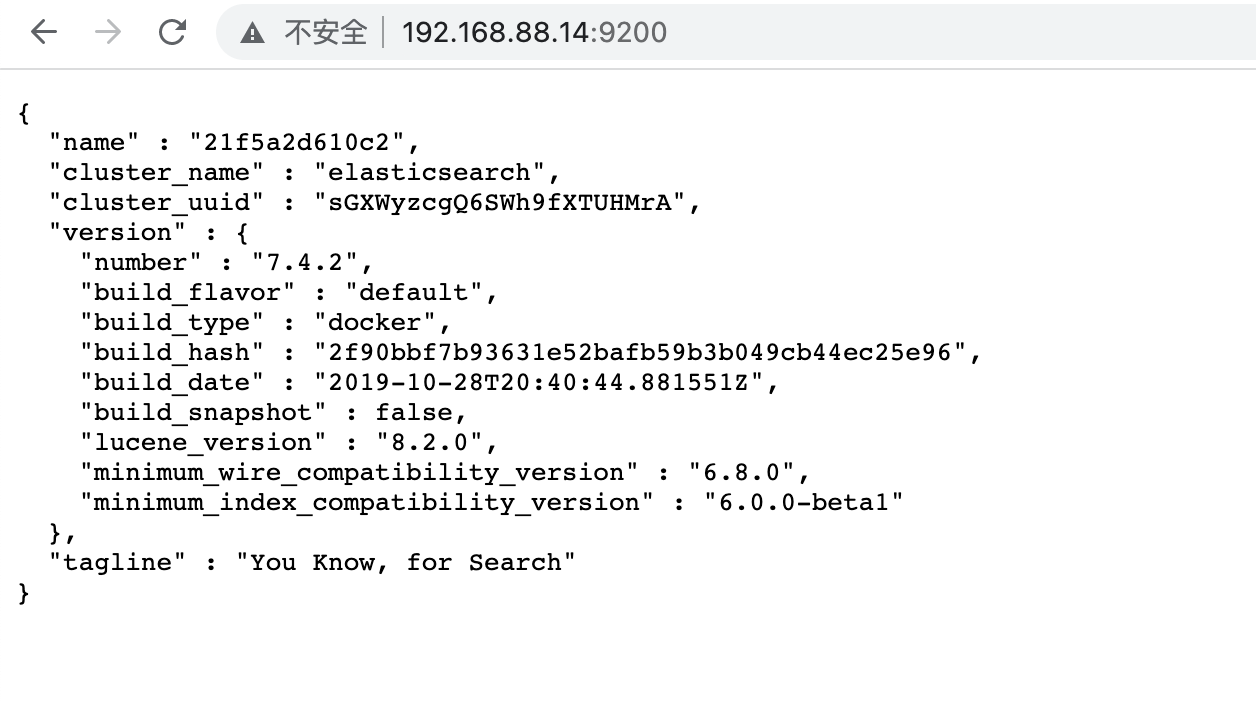
②、Kibana
1 | |
上面的ip地址:http://192.168.88.14:9200 改成自己Elasticsearch上的地址
测试: