哈喽,大家好,我是指北君。
说到集合类,之前介绍的ArrayList类可能是大家日常用的最多的类,但是对于另一个集合类 LinkedList,可能大家用的不多,但是这种链式集合,有些情况确实特别好用。
1、LinkedList 定义
LinkedList 是一个用链表实现的集合,元素有序且可以重复。
1 | |
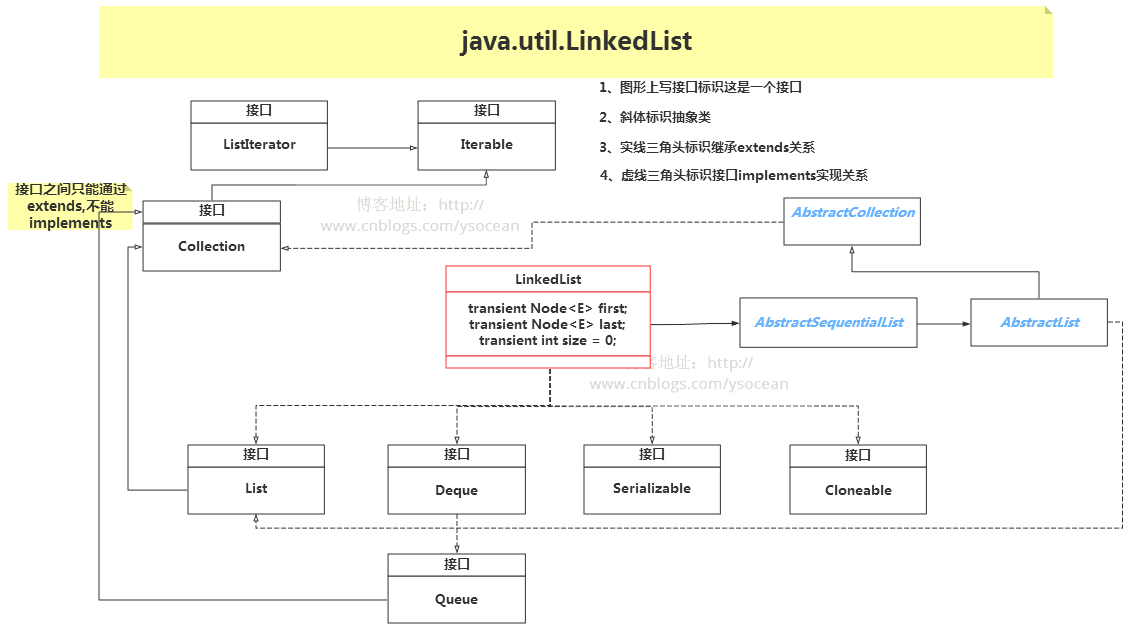 和 ArrayList 集合一样,LinkedList 集合也实现了Cloneable接口和Serializable接口,分别用来支持克隆以及支持序列化。List 接口也不用多说,定义了一套 List 集合类型的方法规范。
和 ArrayList 集合一样,LinkedList 集合也实现了Cloneable接口和Serializable接口,分别用来支持克隆以及支持序列化。List 接口也不用多说,定义了一套 List 集合类型的方法规范。
注意,相对于 ArrayList 集合,LinkedList 集合多实现了一个 Deque 接口,这是一个双向队列接口,双向队列就是两端都可以进行增加和删除操作。
2、字段属性
1 | |
注意这里出现了一个 Node 类,这是 LinkedList 类中的一个内部类,其中每一个元素就代表一个 Node 类对象,LinkedList 集合就是由许多个 Node 对象类似于手拉着手构成。
1 | |
如下图所示:
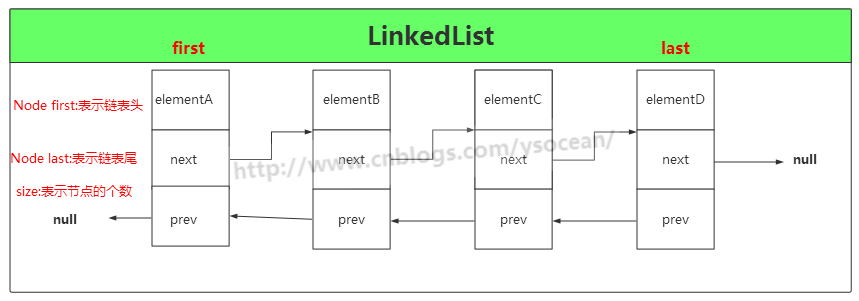 上图的 LinkedList 是有四个元素,也就是由 4 个 Node 对象组成,size=4,head 指向第一个elementA,tail指向最后一个节点elementD。
上图的 LinkedList 是有四个元素,也就是由 4 个 Node 对象组成,size=4,head 指向第一个elementA,tail指向最后一个节点elementD。
3、构造函数
1 | |
LinkedList 有两个构造函数,第一个是默认的空的构造函数,第二个是将已有元素的集合Collection 的实例添加到 LinkedList 中,调用的是 addAll() 方法,这个方法下面我们会介绍。
注意:LinkedList 是没有初始化链表大小的构造函数,因为链表不像数组,一个定义好的数组是必须要有确定的大小,然后去分配内存空间,而链表不一样,它没有确定的大小,通过指针的移动来指向下一个内存地址的分配。
4、添加元素
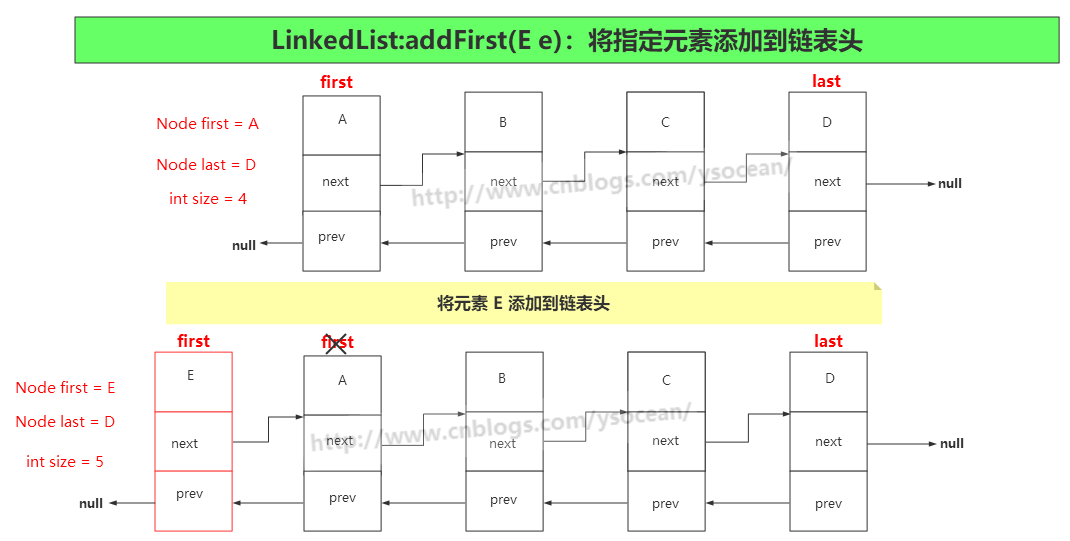
①、addFirst(E e) 将指定元素添加到链表头
1 | |
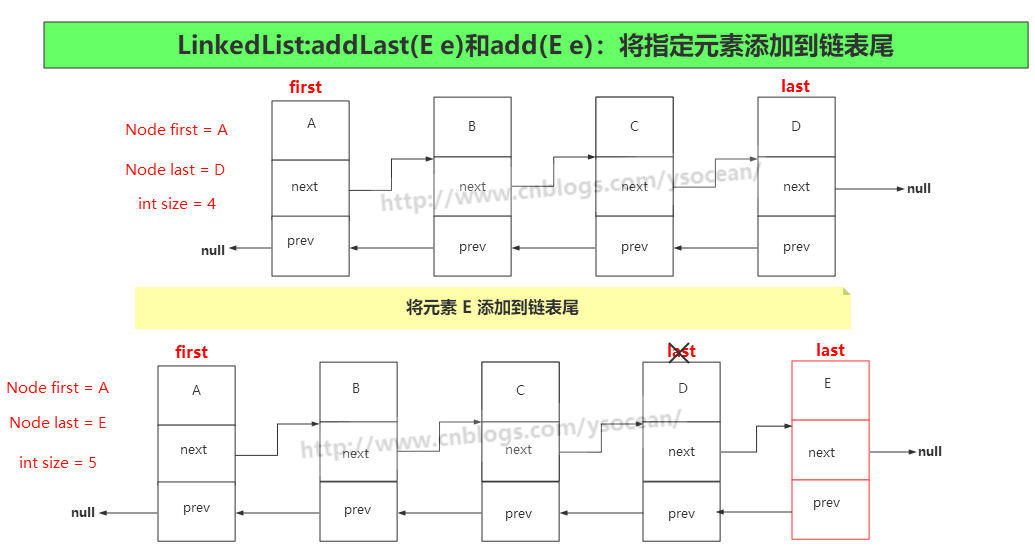
②、addLast(E e)和add(E e) 将指定元素添加到链表尾
1 | |
③、add(int index, E element) 将指定的元素插入此列表中的指定位置
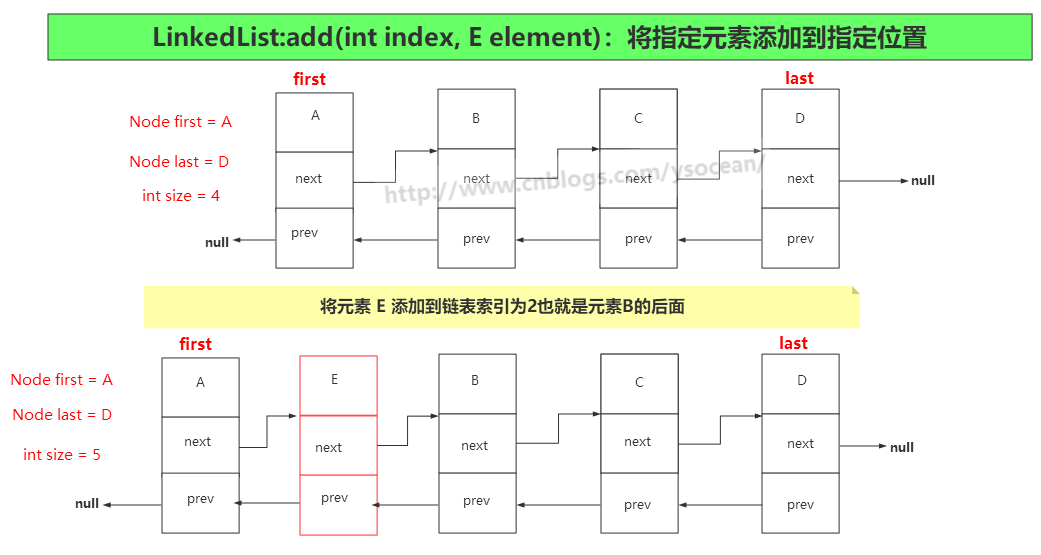
1 | |
④、addAll(Collection<? extends E> c) 按照指定集合的迭代器返回的顺序,将指定集合中的所有元素追加到此列表的末尾
此方法还有一个 addAll(int index, Collection<? extends E> c),将集合 c 中所有元素插入到指定索引的位置。其实
addAll(Collection<? extends E> c) == addAll(size, Collection<? extends E> c)
源码如下:
1 | |
看到上面向 LinkedList 集合中添加元素的各种方式,我们发现LinkedList 每次添加元素只是改变元素的上一个指针引用和下一个指针引用,而且没有扩容。,对比于 ArrayList ,需要扩容,而且在中间插入元素时,后面的所有元素都要移动一位,两者插入元素时的效率差异很大,下一篇博客会对这两者的效率,以及何种情况选择何种集合进行分析。
还有,每次进行添加操作,都有modCount++ 的操作。
5、删除元素
删除元素和添加元素一样,也是通过更改指向上一个节点和指向下一个节点的引用即可,这里就不作图形展示了。
①、remove()和removeFirst() 从此列表中移除并返回第一个元素
1 | |
②、removeLast() 从该列表中删除并返回最后一个元素
1 | |
③、remove(int index) 删除此列表中指定位置的元素
1 | |
④、remove(Object o) 如果存在,则从该列表中删除指定元素的第一次出现
此方法本质上和 remove(int index) 没多大区别,通过循环判断元素进行删除,需要注意的是,是删除第一次出现的元素,不是所有的。
1 | |
6、修改元素
通过调用 set(int index, E element) 方法,用指定的元素替换此列表中指定位置的元素。
1 | |
这里主要是通过 node(index) 方法获取指定索引位置的节点,然后修改此节点位置的元素即可。
7、查找元素
①、getFirst() 返回此列表中的第一个元素
1 | |
②、getLast() 返回此列表中的最后一个元素
1 | |
③、get(int index) 返回指定索引处的元素
1 | |
④、indexOf(Object o) 返回此列表中指定元素第一次出现的索引,如果此列表不包含元素,则返回-1。
1 | |
8、遍历集合
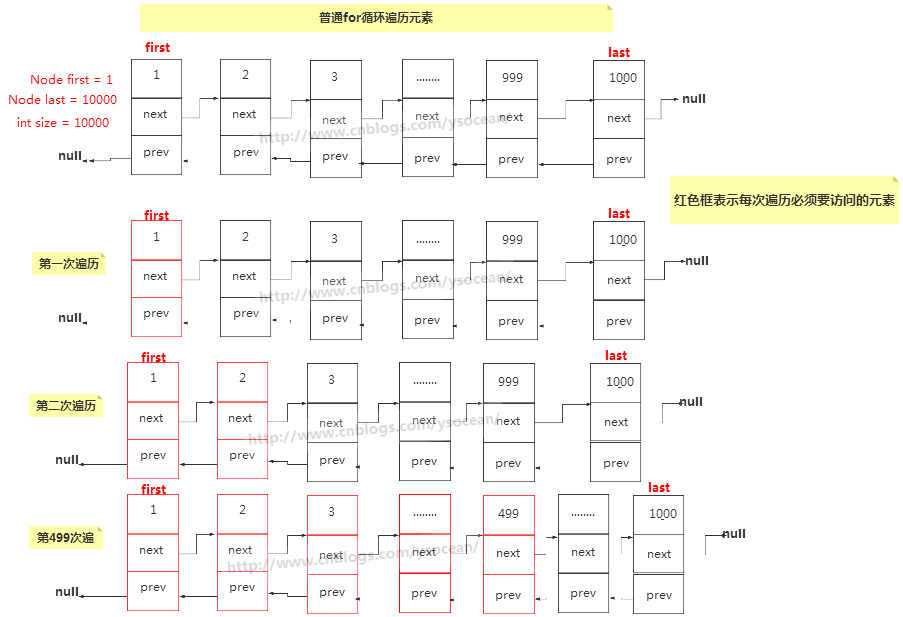
①、普通 for 循环
1 | |
代码很简单,我们就利用 LinkedList 的 get(int index) 方法,遍历出所有的元素。
但是需要注意的是, get(int index) 方法每次都要遍历该索引之前的所有元素,这句话这么理解:
比如上面的一个 LinkedList 集合,我放入了 A,B,C,D是个元素。总共需要四次遍历:
第一次遍历打印 A:只需遍历一次。
第二次遍历打印 B:需要先找到 A,然后再找到 B 打印。
第三次遍历打印 C:需要先找到 A,然后找到 B,最后找到 C 打印。
第四次遍历打印 D:需要先找到 A,然后找到 B,然后找到 C,最后找到 D。
这样如果集合元素很多,越查找到后面(当然此处的get方法进行了优化,查找前半部分从前面开始遍历,查找后半部分从后面开始遍历,但是需要的时间还是很多)花费的时间越多。那么如何改进呢?
②、迭代器
1 | |
在 LinkedList 集合中也有一个内部类 ListItr,方法实现大体上也差不多,通过移动游标指向每一次要遍历的元素,不用在遍历某个元素之前都要从头开始。其方法实现也比较简单:
1 | |
这里需要重点注意的是 modCount 字段,前面我们在增加和删除元素的时候,都会进行自增操作 modCount,这是因为如果想一边迭代,一边用集合自带的方法进行删除或者新增操作,都会抛出异常。(使用迭代器的增删方法不会抛异常)
1 | |
比如:
1 | |
迭代器的另一种形式就是使用 foreach 循环,底层实现也是使用的迭代器,这里我们就不做介绍了。
1 | |
9、迭代器和for循环效率差异
1 | |
打印结果为:
 一万个元素两者之间都相差一倍多的时间,如果是十万,百万个元素,那么两者之间相差的速度会越来越大。下面通过图形来解释:
一万个元素两者之间都相差一倍多的时间,如果是十万,百万个元素,那么两者之间相差的速度会越来越大。下面通过图形来解释:
普通for循环:每次遍历一个索引的元素之前,都要访问之间所有的索引。
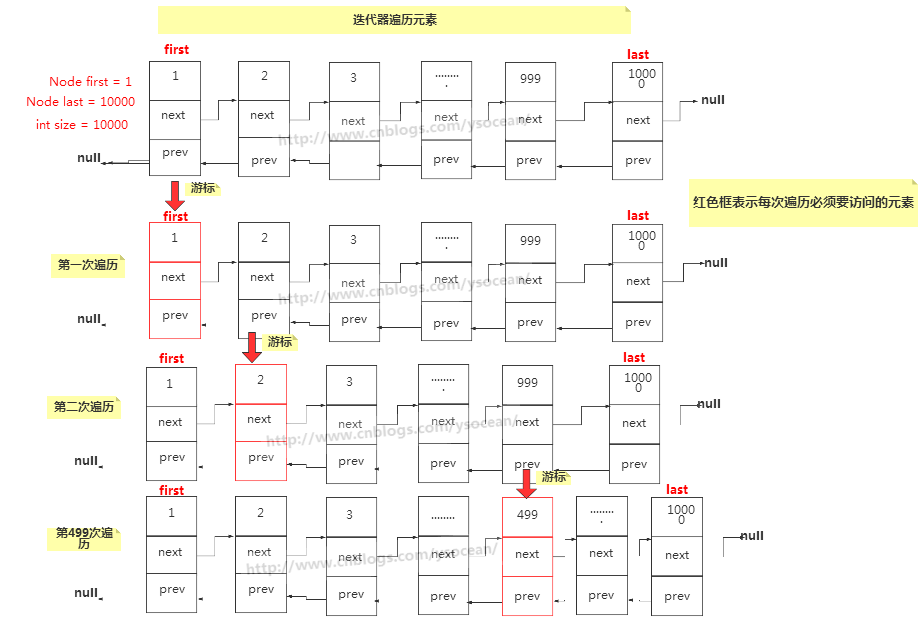 迭代器:每次访问一个元素后,都会用游标记录当前访问元素的位置,遍历一个元素,记录一个位置。
迭代器:每次访问一个元素后,都会用游标记录当前访问元素的位置,遍历一个元素,记录一个位置。
13、小结
好了,这就是JDK中java.util.LinkedList 类的介绍。
我是指北君,操千曲而后晓声,观千剑而后识器。感谢各位人才的:点赞、收藏和评论,我们下期更精彩!
