哈喽,我是指北君。
最近有个读者后台私信指北君,说最近面试被问到了如何解决哈希冲突的问题,他只回答了链地址法(HashMap中就用的这种方法),但是面试官说还有其他的方案,于是想让小北解答下,说实话,当时小北也不知道。。。

不过没关系,不懂就学啊,小北百度了一波后,解答完读者的疑问就记录成了这篇文章
一. 哈希表
在介绍hash冲突的时候,先简单介绍下哈希表,哈希表也叫散列表,是根据关键值Key(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值中的Key映射到表中一个位置来访问记录,以加快查找的速度。其中,映射的实现也叫做哈希函数,而存放记录的数组叫做哈希表,其如下图所示
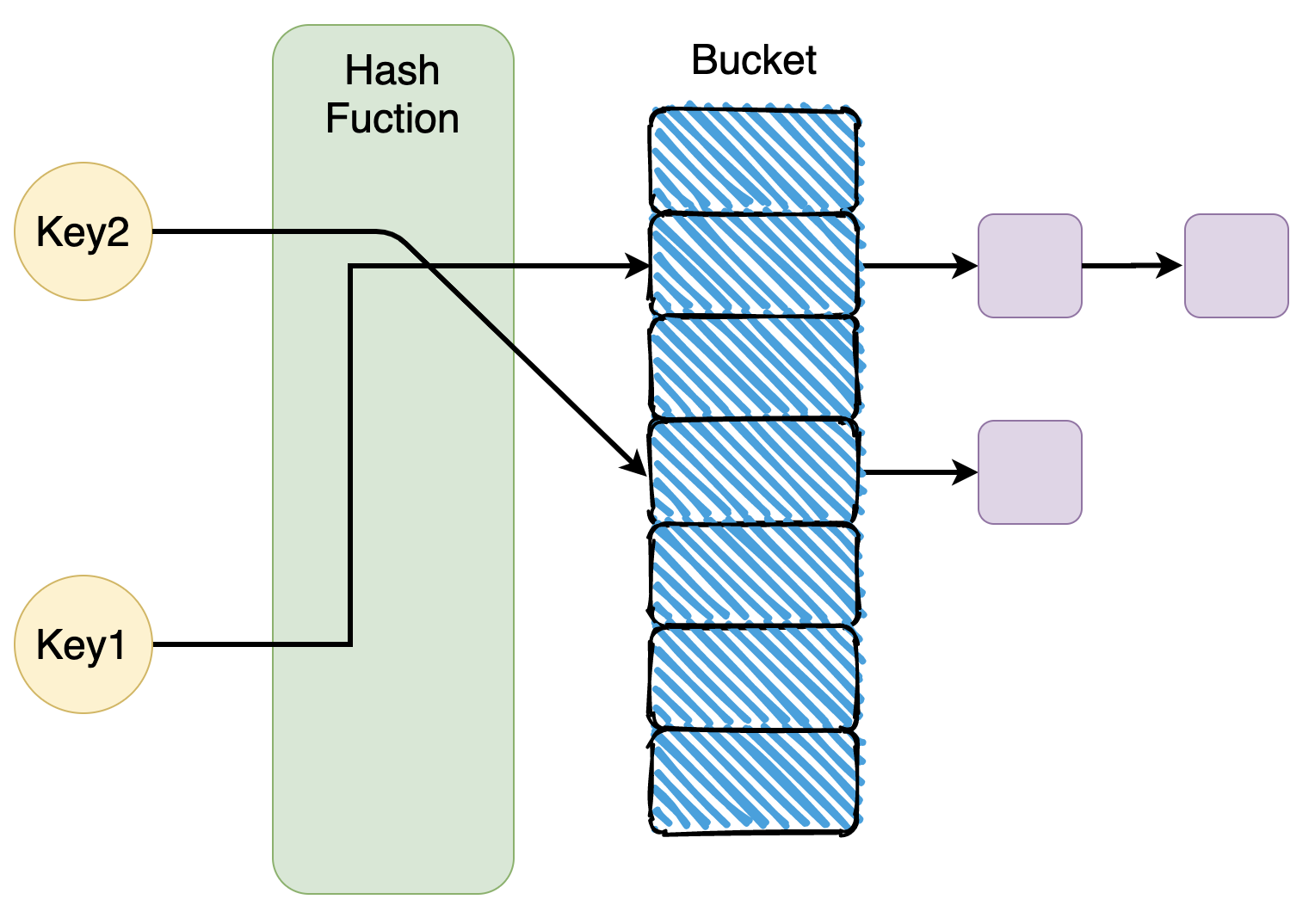
而hash冲突,就是将key通过哈希函数f(key)得到的结果的作为地址去存放当前的值时,发现算出来的地址上已经有人先来了。这就是所谓的hash冲突,下面我们看看具体的解决方案吧。
二. 哈希冲突解决方法
1)链地址法
这种方法是大家最熟悉的,因为Java HashMap中使用的就是这种方法。这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
优点:
- 对于记录总数频繁可变的情况,处理的比较好(也就是避免了动态调整的开销)
- 由于记录存储在结点中,而结点是动态分配,不会造成内存的浪费,所以尤其适合那种记录本身尺寸(size)很大的情况,因为此时指针的开销可以忽略不计了
缺点:
-
由于使用指针,记录不容易进行序列化(serialize)操作
-
存储的记录是随机分布在内存中的,这样在查询记录时,相比结构紧凑的数据类型(比如数组),哈希表的跳转访问会带来额外的时间开销
-
如果所有的 key-value 对是可以提前预知,并之后不会发生变化时(即不允许插入和删除),可以人为创建一个不会产生冲突的完美哈希函数(perfect hash function),此时封闭散列的性能将远高于开放散列
2) 开放定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址 p=f(key) 出现冲突时,以p为key,在通过哈希函数f(p)产生新的哈希地址p1,如果p1仍然冲突,再以p1为key,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。
优点:
- 记录更容易进行序列化操作
- 如果记录总数可以预知,则可以创建完美哈希函数,此时处理数据的效率是非常高的
缺点:
- 存储记录的数目不能超过桶数组的长度,如果超过就需要扩容,而扩容会导致某次操作的时间成本飙升
- 由于记录是存放在桶数组中的,而桶数组必然存在空槽,所以当记录本身大小很大或者记录总数很大时,会导致明显的内存浪费
3) 再哈希法
这种方法是同时构造多个不同的哈希函数,当第一个哈希函数冲突后,我们使用第二个哈希函数,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
4)建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
三. 小结
好了,今天小北介绍了哈希冲突的解决方法,这个在面试中是会被经常问到的,所以大家需要重点关注下。
我是指北君,操千曲而后晓声,观千剑而后识器。感谢各位人才的:点赞、收藏和评论,我们下期更精彩!
