哈喽,大家好,MySQL作为广泛使用的开源关系型数据库管理系统,应该没有Java开发没使用过吧。
关于MySQL,我们大部分时间都在聊,如何提高查询效率,今天我们来聊聊如何提高MySQL的插入效率。
提高插入效率的方式
一般情况下,数据库是运行在专门的服务器上,提高插入效率最明显的当然是提高服务器配置啦。 比如,使用高性能的CPU和SSD磁盘,使用分布式系统架构,将写入压力分散到多个节点。 这个方式的成本也是最高的,老板们当然不会使用这种方式了。
我们还可以从其他方面入手:
- 调整数据库配置:优化缓冲池大小、增大批量插入缓冲区等,通过调整MySQL数据库参数的方式。
- 选择使用
MyISAM存储引擎,因为其简单的表锁机制和无事务开销而在插入速度上表现更优。 - 使用批量插入的方式。
考虑到实际的应用场景,我们最可能操作的就是使用第3种实现方式,通过批量插入的方式来提高效率。
探索批量插入
常用的批量插入的方式有2种:
- 拼接SQL,使用
insert into xxx (...) values (...),(...),(...) - 利用事务,将批量插入操作封装在单个事务中,可以减少事务开销并提高并发性能。
- 在mybatisPlus,以及mybatis-flex中,saveBatch 就是使用的这种方式
接下来我们来测试一下这几个方法。
测试代码
测试的SQL
1 | |
一、使用 batchXml
1 | |
二、使用mybatis-flex提供的saveBatch
1 | |
三、手动控制事务的提交,saveBatchSession
1 | |
启动代码
1 | |
测试结果
使用了3种方式进行测试
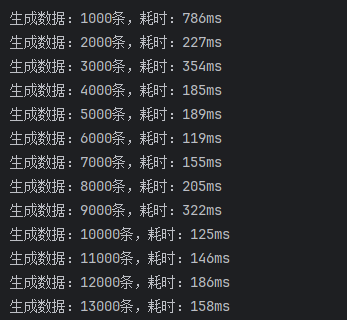
未开启批处理,batchXml
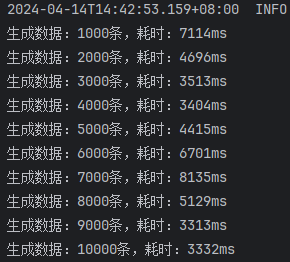
未开启批处理,mybatis-flex提供的saveBatch
未开启批处理,saveBatchSession
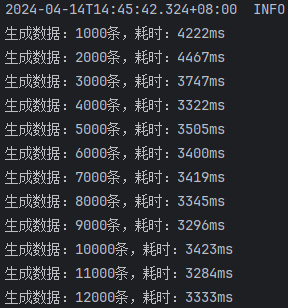
从这里的结果可以看出,使用 batchXml 的效率是最高的,远远超越其他方式。
但是仔细一想,这些数据应该很不正常,插入1000条数据,竟然需要4秒左右,和单条插入1000次的时间几乎没有区别。
开启批处理
经过一番查询资料,并检查配置,发现果然另有玄机,连接数据库的时候没有开启批处理
开启方式:在spring的配置文件中,连接数据源时,url需要增加 allowPublicKeyRetrieval=true
然后重新测试一遍。
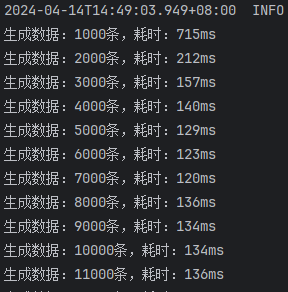
开启批处理,saveBatchXml
开启批处理,mybatis-flex提供的saveBatch
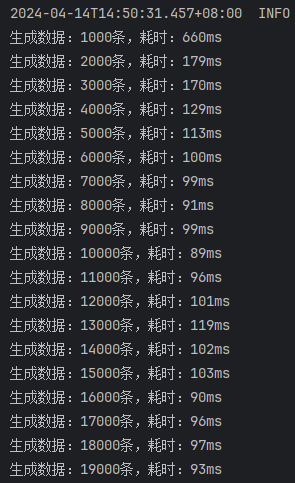
开启批处理,saveBatchSession
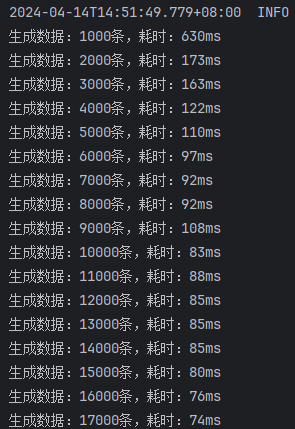
这次的结果就比较正常了,可以看出来:
saveBatchSession最快mybatis-flex提供的saveBatch因为有些额外的操作,多消耗了10ms左右的时间saveBatchXml相较于另外两种方式,慢了30ms~40ms。
接下来,把每批次的处理数据由1000次增加到10000次,再次进行测试。
开启批处理,saveBatchXml,10000条一批次
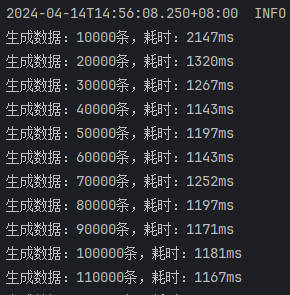
开启批处理,saveBatchSession,10000条一批次
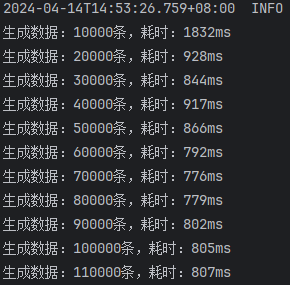
开启批处理,mybatis-flex提供的saveBatch,10000条一批次
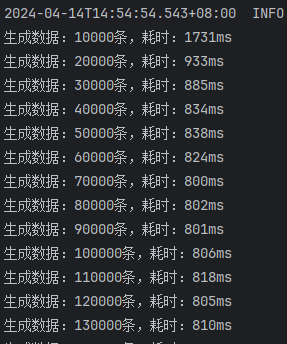
由此结果可以看出来:
saveBatchSession和mybatis-flex提供的saveBatch耗时基本一致saveBatchXml就明显的慢一些,按照效率差算,差了将近50%的效率 \(\text { 效率差 }=\frac{\text { 较长时间 }- \text { 较短时间 }}{\text { 较短时间 }}=\frac{1200 \mathrm{~ms}-800 \mathrm{~ms}}{800 \mathrm{~ms}}\)
总结
综上,提高MySQL插入效率主要可通过调整数据库配置、选择适合的存储引擎以及运用批量插入策略等方式实现。 在实际应用中,尤其是在使用ORM框架进行数据操作时,应合理选择并充分利用批量插入功能,以最大程度提升插入效率。
- 连接数据时,数据源配置文件url加上
allowPublicKeyRetrieval=true - 数据量很大时,使用mybatisPlus或MybatisFlex提供的
saveBatch即可。